

In the last section, we converted our Prompty asset into code and successfully executed the application. In this section, we will cover how we can use Observability in Prompty to debug our application.
1. What we will cover
For observability in Prompty, we will use the tracer to visualize and debug the execution of the Prompty asset through the following steps:
- Understand observability in Prompty
- Build and debug a Prompty asset
- Understand how observability works in your code
- Analyze the trace output to debug and fix the bug
2. Understanding Observability in Prompty
Observability refers to the ability to monitor and understand the behavior of a system based on the data it produces, such as logs, metrics, and traces.. It is important as it provides you with insights on your LLM workflows and provides a way to debug your prompt inputs and outputs.
In Prompty, you can easily trace and visualize flow, which helps you to understand and debug your code using the built-in tracer. Additionally, you can create your own tracer by adding your own hook. By default, Prompty has two traces built-in:
- Console Tracer: This tracer logs the output to the console.
- Prompty Tracer: This tracer logs the output to a JSON file.
3. Modify our Prompty
In our shakespeare.prompty asset we will update the prompt to request for different variations of the same message. The new prompt will be: "Can you create 5 different versions of a short message inviting friends to a Game Night?". Additionally, change the max_tokens: value from 3000 to 150.
Head over to the shakespeare.py file as well and update the question to: "Can you create 5 different versions of a short message inviting friends to a Game Night?".
☑ Function that executes the Prompty asset (click to expand)
1---
2name: Shakespearean Writing Prompty
3description: A prompt that answers questions in Shakespearean style using Cohere Command-R model from GitHub Marketplace.
4authors:
5 - Bethany Jepchumba
6model:
7 api: chat
8 configuration:
9 type: azure_openai
10 azure_endpoint: ${env:AZURE_OPENAI_ENDPOINT}
11 azure_deployment: gpt-4o
12 parameters:
13 max_tokens: 150
14sample:
15 question: Can you create 5 different versions of a short message inviting friends to a Game Night?
16---
17
18system:
19You are a Shakespearean writing assistant who speaks in a` Shakespearean style. You help people come up with creative ideas and content like stories, poems, and songs that use Shakespearean style of writing style, including words like "thou" and "hath”.
20Here are some example of Shakespeare's style:
21- Romeo, Romeo! Wherefore art thou Romeo?
22- Love looks not with the eyes, but with the mind; and therefore is winged Cupid painted blind.
23- Shall I compare thee to a summer's day? Thou art more lovely and more temperate.
24
25example:
26user: Please write a short text turning down an invitation to dinner.
27assistant: Dearest,
28 Regretfully, I must decline thy invitation.
29 Prior engagements call me hence. Apologies.
30
31user:
32{{question}}4. Adding observability to your code
To add a tracer, we have the following in our previously generated code snippet:
1from prompty.tracer import trace, Tracer, console_tracer, PromptyTracer
2
3Tracer.add("console", console_tracer)
4json_tracer = PromptyTracer()
5Tracer.add("PromptyTracer", json_tracer.tracer)
6
7@trace
8def run(
9 question: any
10) -> str:
11
12 # execute the prompty file
13 result = prompty.execute(
14 "shakespeare.prompty",
15 inputs={
16 "question": question
17 }
18 )Tracer.add("console", console_tracer): logs tracing information to the console, useful for real-time debugging.json_tracer = PromptyTracer(): Creates an instance of the PromptyTracer class, which is a custom tracer.Tracer.add("PromptyTracer", json_tracer.tracer): logs tracing in a.tracyJSON file for more detailed inspection after runs, providing you with an interactive UI.@trace: Decorator that traces the execution of the run function.
5: Analyzing and debugging the trace output
The output from the tracer is displayed in the console and in a .tracy file. A new .tracy file is created in a new .runs folder.
The trace output is divided into three: load, prepare and run. Load refers to the loading of the Prompty asset, prepare refers to the preparation of the Prompty asset, and run refers to the execution of the Prompty asset. Below is a sample of the trace output, showing the inputs, outputs, and metrics, such as execution time and token count:
Note: it may take a while for the trace output to appear, and you may need to click several runs before seeing the full trace.
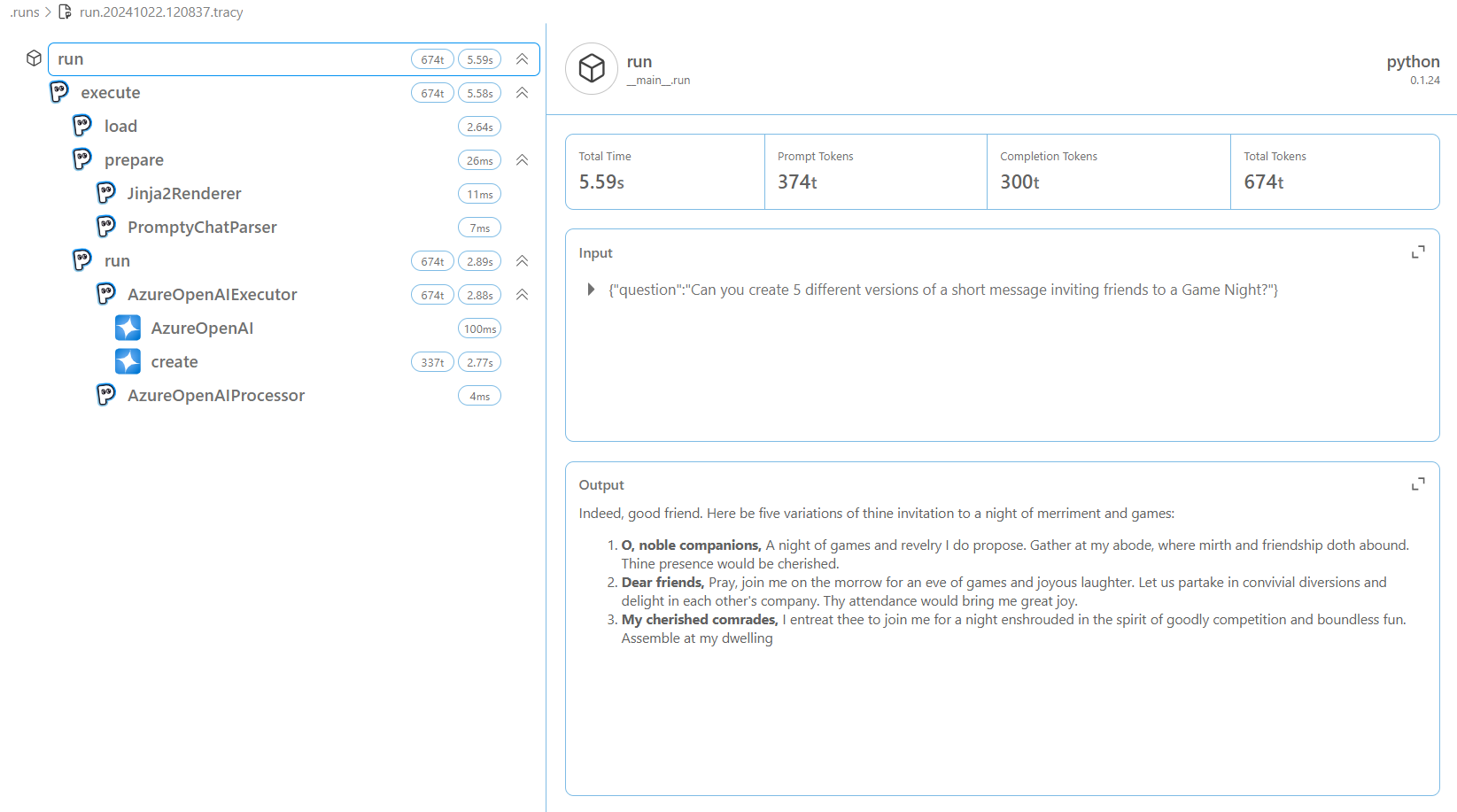
From the trace output, you can see the inputs, outputs and metrics such as time to execute the prompt and tokens. This information can be used to debug and fix any issues in your code. For example, we can see output has been truncated and the Completion Tokens count is less than 1000, which might not be sufficent for the prompt to generate different outputs. We can increase the max_tokens in our Prompty to 1000 to generate more tokens. Once done, run the code again and confirm you get 5 examples of the short message inviting friends to a Game Night.
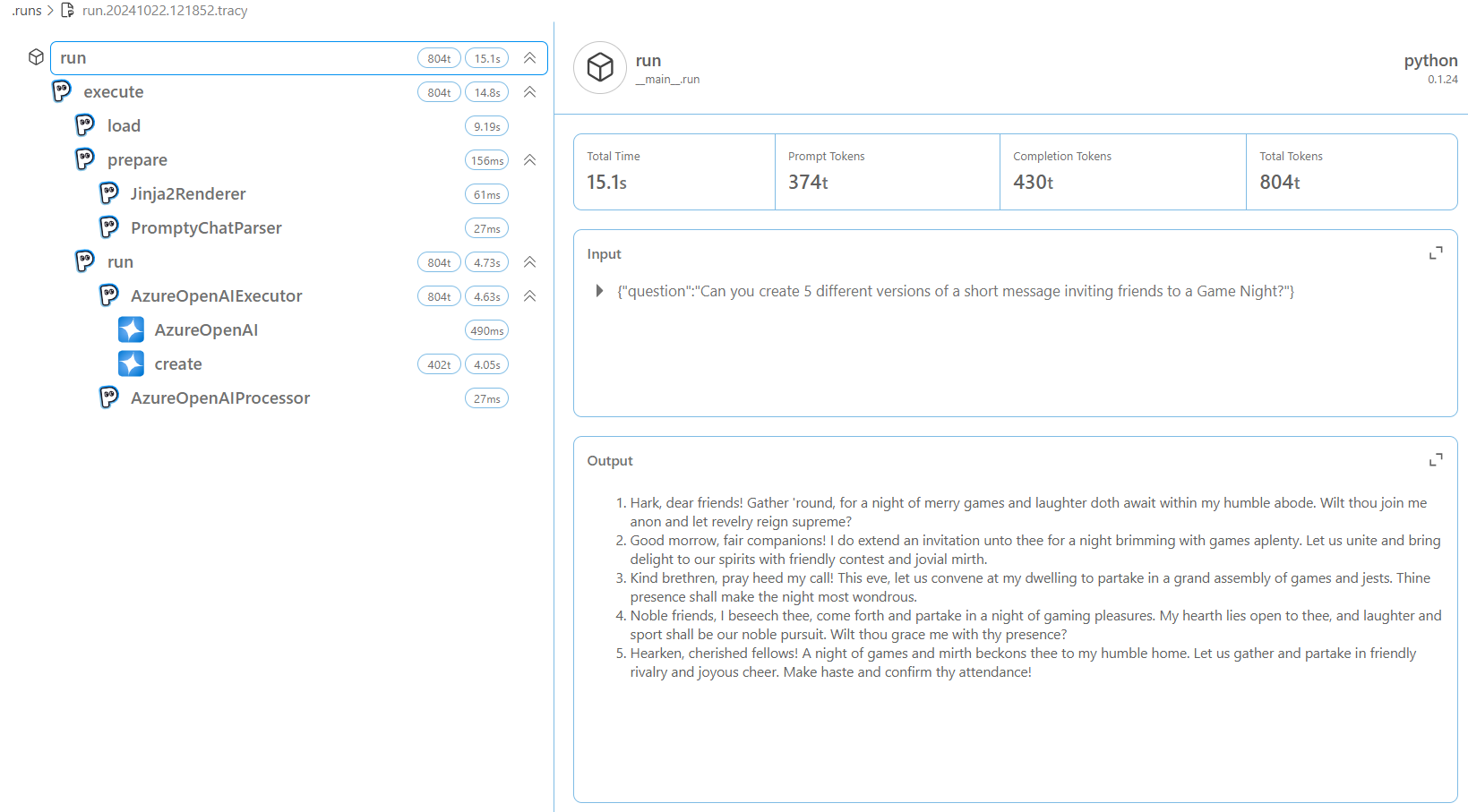
You can continue experimenting with different parameters such as temperature and observe how it affects the model outputs.
6. Using observability for Model Selection
Another way to make the most of observability is in Model Selection. You can switch between models and observe their performance such as completion tokens, latency and accuracy for different tasks. For example, you can switch between the gpt-4o and gpt-35-turbo models and observe the performance of each model. You can also leverage on GitHub Models, Azure OpenAI and other models to observe the performance of each model. Below is a comparison of the trace output for the gpt-4o and gpt-35-turbo models:
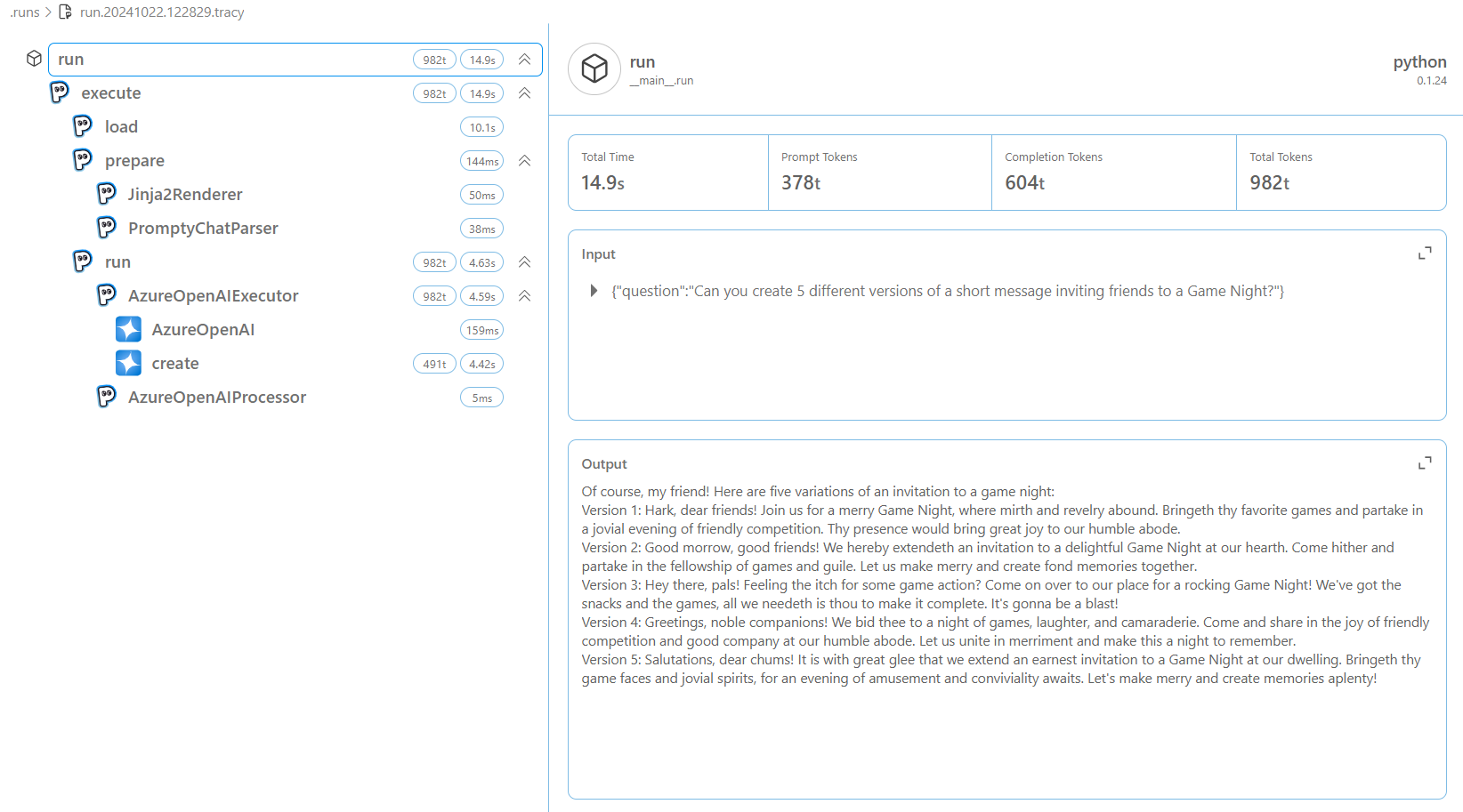
From the output, you can see the difference in the completion tokens and the time taken to execute the prompt. This information can be used to select the best model for your use case.
7. Building a Custom Tracer in Prompty
In the guides section, we will provide a deep dive into Observability in Prompty and how you can create your own tracer.
Want to Contribute To the Project? - Updated Guidance Coming Soon.